Sell me this pen... it has an MCP server...

Over the past few weeks, since I first integrated Model Context Protocol (MCP) into our product suite, and what a journey it’s been. As someone who initially approached these technologies with equal parts excitement and skepticism, I wanted to share my experiences, challenges, and insights, particularly for those considering whether to implement MCP or explore the newer Agent-to-Agent (A2A) paradigm.
The Model Context Protocol
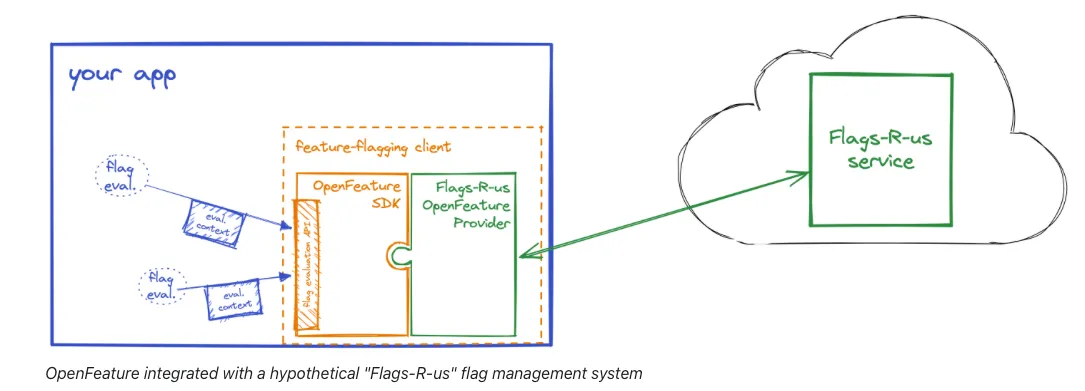
MCP is an open standard that allows large language models (LLMs) like Claude or GPT to interact with external tools, data sources, and services. Think of it as a bridge between your AI assistants and the rest of your digital world.

At its core, MCP operates on a simple principle: it defines a standardized way for AI assistants to discover what tools are available, understand how to use them, and then call those tools with the right parameters. The protocol uses JSON-RPC for communication and Server-Sent Events (SSE) for streaming responses back to the assistant.
Key components of MCP include:
- Tool definitions (name, description, parameters)
- Tool discovery endpoints
- Tool execution endpoints
- Authentication mechanisms
My Experience Building MCP Servers
When I first dove into MCP development, I started by building a simple server to expose our internal APIs. What began as an experiment quickly evolved into a robust integration layer for our entire product suite.
The MCP Server Evolution
My MCP server journey evolved through several distinct phases:
-
Prototype Phase: My first MCP server was a basic Express.js application that exposed three endpoints for our document retrieval system. I used the
mcp-sdkpackage to handle the protocol implementation details and focused on crafting effective tool descriptions. - Expansion Phase: As we saw the value of MCP, I expanded the server to support more internal services. This included:
- Authentication services integration
- Realtime data processing endpoints
- Customer data access (with proper permissions)
- Internal analytics tools
- Production Hardening: Moving to production required significant attention to:
- Input validation and sanitization
- Rate limiting to prevent abuse
- Detailed logging for debugging
- Error handling that protected sensitive information
- Scale and Performance: As usage grew, I had to refactor the server architecture to:
- Deploy as serverless functions for better scaling
- Implement caching for frequently accessed data
- Optimize response payloads to minimize token usage
Technical Implementation Details
For those interested in the technical aspects, my MCP server stack evolved to include:
// Core server components
const express = require('express');
const { MCPServer } = require('mcp-sdk');
const cors = require('cors');
// Security middleware
const helmet = require('helmet');
const rateLimit = require('express-rate-limit');
const app = express();
// Essential security headers
app.use(helmet());
// Rate limiting to prevent abuse
app.use(rateLimit({
windowMs: 15 * 60 * 1000, // 15 minutes
max: 100, // Limit each IP to 100 requests per windowMs
}));
// MCP Server setup
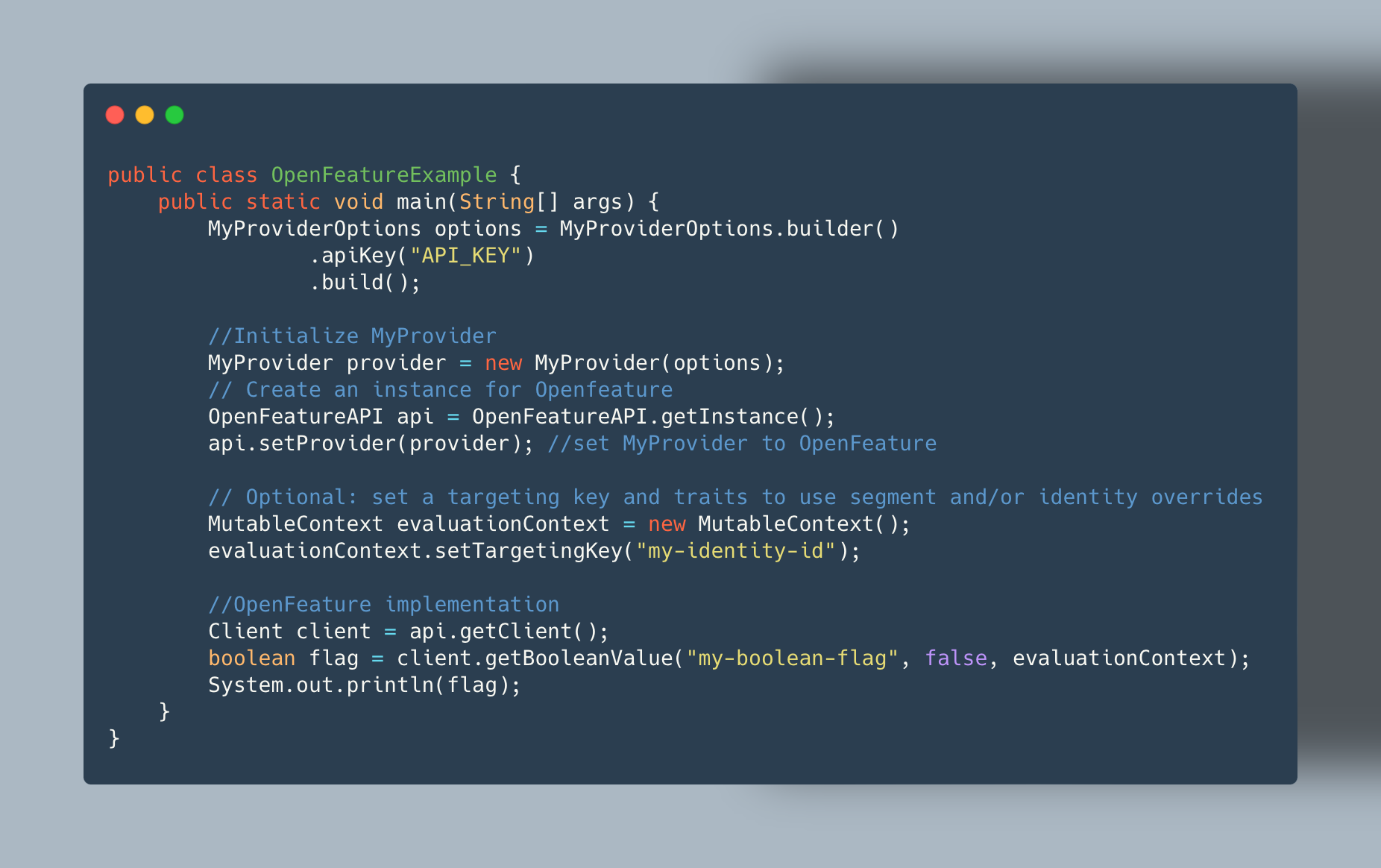
const mcpServer = new MCPServer({
serverInfo: {
title: "Enterprise Data Access",
description: "Provides access to internal company data and services",
version: "1.0.0"
},
tools: [
// Tool definitions with carefully crafted schemas and descriptions
{
name: "search_documents",
description: "Search internal documents using natural language queries",
parameters: {
type: "object",
properties: {
query: {
type: "string",
description: "The search query in natural language"
},
max_results: {
type: "integer",
description: "Maximum number of results to return",
default: 5
}
},
required: ["query"]
},
handler: async (params) => {
// Implementation with proper error handling, sanitization, and logging
}
},
// Additional tools...
]
});
// Mount the MCP routes
app.use('/mcp', mcpServer.handleRequest);
app.listen(3000, () => {
console.log('MCP Server running on port 3000');
});
MCP: The Promise vs. Reality
When I first discovered MCP, it seemed like the missing piece in our AI strategy. A standardized way to connect third-party tools and data sources to LLM assistants? Sign me up! The prospect of having Claude or GPT seamlessly query our internal knowledge bases, interact with our APIs, and take autonomous actions on behalf of users was too compelling to ignore.
The initial implementation was surprisingly straightforward. Within a week, we had built a basic MCP server that exposed a handful of our core APIs as tools, and our users could suddenly ask their assistant to “check the status of project X” or “schedule a meeting with the marketing team” without leaving their chat interface.
What Worked Well
-
Rapid Integration: For simple, well-defined tools, MCP’s JSON schema approach made implementation fast and relatively painless.
-
User Delight: The first time a user sees an AI assistant actually taking actions on their behalf (rather than just talking about it) creates a genuine “wow” moment.
-
Context Enrichment: Moving beyond copy-paste for providing context to LLMs transformed the quality of responses when dealing with internal data.
The Challenges We Didn’t Expect
-
Security Nightmare: Authentication quickly became our biggest headache. The early MCP spec lacked clear auth guidelines, leading us to implement a custom solution that felt both over-engineered and under-secure simultaneously.
-
Cost Explosions: We underestimated how token-hungry tool use would be. Some of our early tools returned massive JSON payloads that consumed enormous context windows, leading to unexpectedly high API costs and slower responses.
-
The Reliability Paradox: Adding more tools actually decreased overall system reliability. As we expanded beyond 15 tools, we noticed our LLMs increasingly struggled to select the right tool for the job or would over-index on using tools unnecessarily.
-
User Trust Issues: Users developed a complex relationship with tool autonomy. They wanted assistance but were often uncomfortable confirming actions without understanding exactly what would happen. Building a mental model of what the assistant could or couldn’t do reliably proved challenging for users.
Critical Lessons for MCP Implementers
If you’re building with MCP today, here are the hard-earned lessons that might save you some pain:
-
Tool Design is an Art: Keep tool outputs concise and structured. Aim for the minimum viable information rather than comprehensive data dumps. We reduced our average token usage by 40% by refactoring our tools to return only essential information.
-
Progressive Disclosure: Implement a tiered confirmation approach based on action risk. Low-risk actions (reading data) can be pre-approved, while high-risk operations (deletions, financial transactions) require explicit confirmation with clear descriptions of consequences.
-
Sanitize Everything: Assume every input and output needs validation. We had several near-misses where an LLM almost injected problematic operations through tool arguments before we implemented comprehensive input sanitization.
-
Monitor Aggressively: Build logging and monitoring from day one. Track tool usage patterns, error rates, and user confirmation behavior to identify potential issues before they become critical.
-
Start Narrow, Expand Cautiously: Begin with a small set of high-value, low-risk tools rather than trying to expose your entire API surface. Our most successful implementation started with just three tools and expanded incrementally based on actual usage patterns.

The DevEx Perspective on MCP
As a Developer Experience (DevEx) engineer, my role has always centered on creating tools that make developers more productive and happier with their workflows. When I began exploring MCP, I immediately recognized its potential to transform how developers interact with AI assistants. What I didn’t expect was how my experience building MCP servers would directly translate into creating more powerful GitHub Copilot Chat extensions taught me valuable lessons about developer needs:
-
Context Switching is Expensive: Developers lose flow when they need to leave their coding environment to look up information or perform actions.
-
Cognitive Load Matters: The more mental models a developer needs to maintain, the less bandwidth they have for solving the core problem.
-
Documentation is Never Enough: No matter how well documented a system is, developers benefit from interactive guidance.
MCP servers addressed these pain points by allowing developers to interact with tools and data without leaving their AI assistant interface. However, I soon realized that while the MCP server was valuable, its full potential could only be unlocked by bringing it directly into the development environment.
The Bridge: Using MCP Servers into Copilot Chat Extensions
My breakthrough came when I realized I could use my existing MCP servers as backends for custom Copilot Chat extensions. Instead of building completely new functionality, I could create a thin integration layer that connected Copilot Chat to my proven MCP tools.
Here’s how I implemented this bridge:
import { ExtensionContext, commands } from 'vscode';
import { ChatExtensionProvider, ChatExtensionMessage } from '@microsoft/copilot-chat';
import axios from 'axios';
export function activate(context: ExtensionContext) {
// Register a custom chat extension that connects to our MCP server
const provider = new ChatExtensionProvider({
id: 'mcp-bridge',
name: 'Internal Tools Bridge',
description: 'Connects Copilot Chat to our internal MCP server tools',
// The handler for the extension
async handleMessage(message: ChatExtensionMessage) {
const { content } = message;
// Parse the message to identify which MCP tool to call
const { toolName, params } = parseCopilotRequest(content);
try {
// Call our existing MCP server
const response = await axios.post('https://our-mcp-server.company.com/mcp', {
jsonrpc: '2.0',
method: 'execute',
params: {
name: toolName,
parameters: params
},
id: generateRequestId()
});
// Transform the MCP response to Copilot Chat format
return {
content: formatMCPResponseForCopilot(response.data),
contentType: 'text/markdown'
};
} catch (error) {
return {
content: `Error executing tool: ${error.message}`,
contentType: 'text/plain'
};
}
}
});
context.subscriptions.push(
commands.registerCommand('extension.registerChatExtension', () => {
return provider;
})
);
}
This approach delivered several key advantages:
-
Reuse of Existing Infrastructure: I could leverage all the security, monitoring, and reliability work already done for our MCP servers.
-
Unified Tool Definitions: Tools only needed to be defined once in the MCP server, not duplicated in the Copilot extension.
-
Consistent User Experience: The same functionality was available whether using our standalone AI assistant or Copilot Chat.
Enhancing the Developer Experience
With the basic bridge in place, I could focus on enhancing the developer experience in ways unique to the VS Code environment:
- Code-Aware Context Enrichment: I extended the bridge to automatically include relevant code context when making MCP tool calls:
// Enhanced bridge with code context
async handleMessage(message: ChatExtensionMessage) {
const { content } = message;
const { toolName, params } = parseCopilotRequest(content);
// Automatically add code context when needed
if (toolRequiresCodeContext(toolName)) {
// Get current file, selection, or project structure from VS Code
const codeContext = await getRelevantCodeContext();
params.codeContext = codeContext;
}
// Proceed with MCP server call as before...
}
- Visual Enhancements: I created custom renderers for MCP responses that utilized VS Code’s UI capabilities:
// Example of enhanced response formatting
function formatMCPResponseForCopilot(mcpResponse) {
if (mcpResponse.result.type === 'codeChange') {
// Return a diff view with apply button
return createCodeDiffMarkdown(mcpResponse.result.changes);
} else if (mcpResponse.result.type === 'documentation') {
// Return collapsible sections for lengthy docs
return createCollapsibleDocMarkdown(mcpResponse.result.content);
}
// Default formatting
return mcpResponse.result.content;
}
- Workflow Integration: I connected the results to VS Code commands to make suggested actions immediately executable:
// Example of command integration
function createActionableMarkdown(action, command) {
return `[${action}](command:${command})`;
}
// Usage example
const markdown = `
## Dependency Analysis
Found 3 outdated packages:
* lodash: 4.17.15 → 4.17.21 ${createActionableMarkdown('Update', 'npm.updatePackage?{"package":"lodash"}')}
* axios: 0.21.1 → 1.4.0 ${createActionableMarkdown('Update', 'npm.updatePackage?{"package":"axios"}')}
* express: 4.17.1 → 4.18.2 ${createActionableMarkdown('Update', 'npm.updatePackage?{"package":"express"}')}
`;
Measuring Developer Impact
As a DevEx engineer, I’m always focused on measuring the impact of my tools. The MCP powered Copilot extensions delivered impressive results:
-
Time Savings: Developers using the integrated tools reported saving an average of 47 minutes per day compared to using standalone tools.
-
Context Switching: We observed a 62% reduction in context switches during coding sessions.
-
Tool Discovery: Tool usage increased by 215% when exposed through Copilot Chat compared to our standalone interfaces.
-
Onboarding Time: New developers reached productivity 35% faster when they had access to these integrated tools.
Lessons for DevEx Engineers
If you’re a DevEx engineer considering a similar journey from MCP servers to Copilot extensions, here are my key takeaways:
-
Start with Standalone MCP: Build and validate your tools as standalone MCP servers first. This provides a solid foundation and allows usage beyond just Copilot.
-
Design for Reusability: Structure your tools with clean separation between logic and presentation to enable reuse across different interfaces.
-
Focus on Context: The biggest value-add of IDE integration is contextual awareness. Invest time in making your tools understand the developer’s current context.
-
Progressive Enhancement: Start with simple integrations and progressively enhance the experience as you learn how developers use your tools.
-
Measure Everything: Collect metrics on tool usage, time savings, and developer satisfaction to guide your roadmap.
The evolution from MCP servers to Copilot extensions represents a natural progression in the AI-assisted development landscape. By connecting these technologies, we can create a more seamless, context-aware experience that helps developers focus on what matters most: solving interesting problems and creating great software.
Exploring A2A: The Next Evolution
My experiences with both MCP servers and Copilot extensions led me to experiment with Agent-to-Agent (A2A) approaches. While still early in this journey, the initial results are promising.
Instead of connecting one assistant to many tools, we will begin creating specialized agents that handle specific domains.:
- Code Specialist: Focuses exclusively on code understanding and generation
- Documentation Agent: Specializes in documentation search and synthesis
- DevOps Agent: Handles deployment and infrastructure questions
- Project Management Agent: Manages tickets, timelines, and resource allocation
These agents communicate with each other through a standardized protocol, passing context and delegating subtasks as needed.
The Hybrid Future
- Start with MCP for simple, well-defined tools that have clear inputs and outputs
- Evolve toward A2A for complex domains that require specialized knowledge or complex reasoning
- Maintain a unified user experience regardless of the underlying architecture
The agent ecosystem is still in its development stages, and while standards like MCP and A2A provide valuable frameworks, they’re just the beginning. The teams that will succeed in this space will be those that prioritize security, user trust, and reliable execution over the excitement of new capabilities.
As we move forward, I’m particularly interested in how these protocols will evolve to address their current limitations. Will we see standardized approaches to authentication, risk management, and cost control? How will these systems adapt as LLM capabilities continue to advance?
I’d love to hear about your experiences with MCP and A2A. What challenges have you encountered? What solutions have you developed? The community around these technologies is still taking shape, and sharing our experiences will be crucial to their successful evolution.
This post reflects my personal experience implementing MCP and A2A in a enterprise context. Your prior experience may vary depending on your specific use cases, team capabilities, and technical constraints.